
Why Authorization Is the Hard Problem in Agentic AI

Summary
Agentic AI systems expose the limits of static authorization models, which assume permissions can be decided once and remain valid over time. As agents plan, act, and replan, authorization must become a continuous feedback signal that constrains behavior at each step rather than a one-time gate. Dynamic, policy-based authorization enables delegation to be enforced through purpose, scope, conditions, and duration, turning denial into a productive signal that guides replanning instead of a terminal failure.

In an earlier post, AI Is Not Your Policy Engine, I argued that even highly capable AI systems should not be making authorization decisions directly. Large language models can explain policies, summarize rules, and reason about access scenarios, but enforcement demands determinism, consistency, and auditability in ways probabilistic systems cannot provide.
That raises the question: If AI systems aren’t the policy engine, what role should they play as systems become agentic and able to pursue goals, generate plans, and take action over time? This is where authorization becomes difficult in a way it never was before.
Most authorization systems today are built around standing authority. A principal is assigned roles, scopes, or permissions, and those permissions remain in force until they are changed or revoked. Standing authority works well for people and services that perform known functions within well-understood boundaries. It answers a simple question: what is this identity generally allowed to do?
Agentic systems don’t fit that model.
An agent is not merely executing predefined requests. It interprets intent, evaluates alternatives, retries when blocked, and chooses what to do next. Treating an agent like a traditional service by giving it a role and a token implicitly grants it standing authority beyond what the invoking principal intentionally delegated. Standing authority works because we trust people in roles to exercise judgment; agentic systems demand tighter, explicit bounds.
What agentic systems require instead is delegated authority: authority that is explicitly derived from another principal and constrained by purpose, context, and time. Standing authority depends on who you are; delegated authority depends on why you are acting.
In practice, delegation cannot live inside identities or tokens alone. It requires policy that can be evaluated at runtime, using context about the action being attempted, the purpose behind it, and the conditions under which it occurs. Systems built around standing authority tend to encode permissions ahead of time. Systems built for delegated authority rely on policy to decide, at the moment of action, whether that delegation still holds.
That distinction matters because agents do not act for themselves. They act on behalf of someone or something else: a person, a team, an organization, or a system goal. Their authority should be bounded by that delegation, not by a broad identity-based role that persists beyond the scope and duration of the original delegation.
Once systems become agentic, authorization is no longer just about controlling access to APIs or resources. It becomes about controlling the scope of autonomy a system is allowed to exercise. The shift from identity-based standing authority to purpose-driven delegated authority is where many existing authorization assumptions begin to break down.
Agentic AI doesn’t make authorization less important. It makes it one of the most criticals parts of the system to get right.
From Standing Authority to Delegated Intent
Traditional authorization systems are organized around requests. A caller asks to perform an action on a resource, and the authorization system decides whether that action is allowed. The request is the unit of control. Once the decision is made, the system moves on.
Agentic systems operate differently.
An agent is typically given a goal rather than a request. From that goal, it derives a sequence of actions, often adapting its plan as it encounters new information or constraints. Authorization decisions are no longer isolated events. They shape what options the agent considers, what paths it explores, and how it responds when an action is denied.
This shift from requests to intent has important implications for authorization. In a request-driven system, authority can often be attached directly to the caller. In an agentic system, authority must be evaluated in relation to the purpose of the action. The same agent, acting under the same identity, may be permitted to perform an action in one context and denied in another, depending on why it is acting.
This is why delegated authority becomes essential. Delegation links authority to intent rather than identity. It allows a principal to grant an agent limited authority to act on its behalf for a specific purpose and duration, without granting the agent broad, standing permissions. When the purpose no longer applies, the delegation should no longer hold. This is why delegation cannot be modeled as a static attribute of an agent’s identity. Delegation depends on purpose, context, and conditions that must be evaluated at the moment of action. In agentic systems, delegation is not an identity property. It is a policy decision.
In practical terms, this means authorization decisions cannot be made once and forgotten. They must be evaluated continuously, as the agent executes it’s plan, taking changing context into account. Authorization becomes part of the feedback loop that governs agent behavior, not just a gate at the edge of the system.
This is also where many existing authorization systems struggle. They are optimized to answer whether a request is allowed, not whether a course of action remains appropriate. Without explicit support for delegated intent, systems fall back to standing authority, granting agents more autonomy than was originally intended.
What Do We Mean by Delegation?
Delegation is an overloaded term. In different contexts, it can mean impersonation, role assumption, or simply acting on behalf of another system. For agentic systems, we need a more precise definition.
In this context, delegation means the explicit, limited transfer of authority from one principal to another to act on its behalf for a specific purpose, under defined conditions, and for a bounded period of time.
Delegation does not grant standing permissions. It grants authority to pursue a specific goal. As such, delegation has three defining characteristics:
Purpose-bound—Delegation is always tied to why an action is being taken. The same action may be permitted or denied depending on the intent it serves.
Context-dependent—Delegation depends on conditions that may change over time, including system state, environment, risk, or approval. Authorization decisions must be evaluated at the moment of action, using the conditions under which the delegation applies.
Time- and scope-limited—Delegation is inherently temporary and bounded. It is not meant to persist beyond the task or conditions that justified it.
Because delegation is purpose-bound, context-dependent, and time-limited, it cannot be represented as a static property of an agent’s identity. In agentic systems, delegation must be expressed and enforced through policy.
Why Agent Behavior Changes Authorization
At a high level, the way agents operate is no longer theoretical. Modern agent frameworks make the agent loop explicit and concrete. A representative example is the architecture for OpenClaw, which documents an agent as a system that repeatedly assembles context, invokes a model, proposes actions through tools, observes outcomes, and updates state before continuing.
In these architectures, a single goal can result in multiple tool invocations across an extended run. The agent may revise its plan as it encounters new information, retries failed steps, or adjusts its approach based on intermediate results. This iterative structure is not an implementation detail. It is the defining characteristic of agentic behavior.
Static authorization models assume a different shape. They are built around discrete requests, where a single decision is made before an action is executed. Once that decision is rendered, the system moves on. That assumption breaks down in agentic systems, where a goal unfolds through a sequence of decisions rather than a single request.
In an agent loop like OpenClaw’s, each proposed tool invocation represents a decision point where authority matters. Authorization is no longer something that happens once at the edge of execution. It must occur repeatedly, as the agent moves from planning to action, and as context changes. The following diagram makes that explicit.
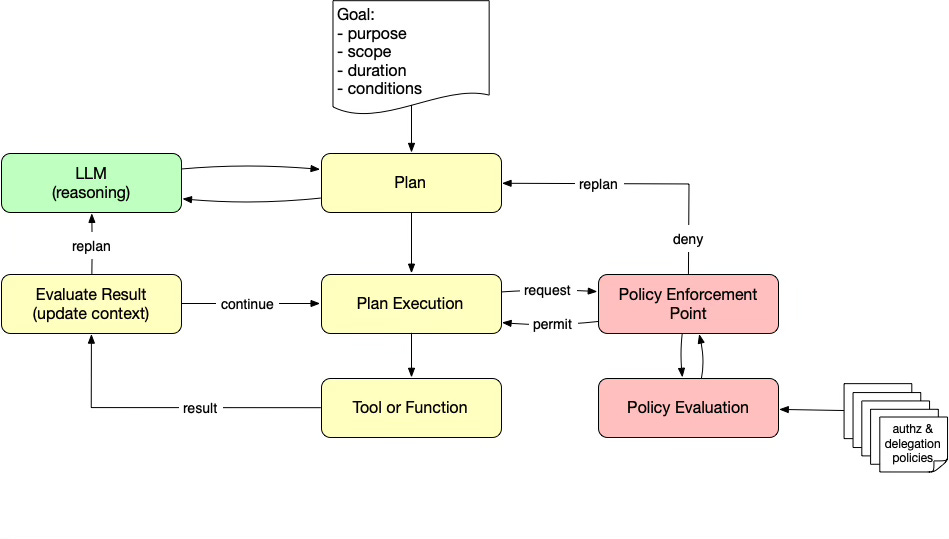
The loop begins with a goal that defines the delegation. Purpose, scope, duration, and conditions frame what the agent is allowed to do and why. This delegation does not grant standing permissions. It constrains the space in which the agent is allowed to plan and act.
From that goal, the agent produces a plan with the help of an LLM. The plan represents a tentative sequence of steps, not commitments to act. As the agent moves into plan execution, each step is treated as a proposed action rather than an automatic operation.
Before any action is carried out, it is sent to a policy enforcement point (PEP). The PEP consults the policy engine, which evaluates the request against authorization and delegation policies using the current context. A permitted action proceeds to the tool or function. A denied action does not end the loop. Instead, the denial feeds back into planning. The denial becomes a productive signal, narrowing options, triggering escalation, or redirecting the agent toward an alternative approach.
When a tool is executed, its result updates the agent’s context. The agent then evaluates the outcome and decides whether to continue, adjust its plan, or replan entirely. Replanning may be triggered by failures, new information, or authorization decisions that constrain what actions remain available.
The addition of the policy engine is the key modification to the agent loop as it is commonly described today. Authorization is no longer a single gate that precedes execution. It is a recurring control signal inside the loop. Policy decisions shape which actions the agent can consider next, not just which ones it may execute.
By inserting authorization explicitly into the cycle, policy becomes part of the control structure that governs agent behavior. As plans evolve and conditions change, delegation is continuously enforced, ensuring the agent remains within the bounds of the authority it was given.
Where This Leaves Us
Agentic AI systems do not simply introduce new execution patterns. They change the role authorization plays in the system. When agents plan, adapt, and act over time, authority can no longer be granted once and assumed to hold. It must be enforced continuously, step by step, as part of the agent’s control loop.
This is why standing authority breaks down in agentic systems. Long-lived roles and tokens assume stable intent and predictable behavior. Agents operate under evolving goals, shifting context, and partial information. Treating them like traditional services implicitly grants more autonomy than is justified by the scope and conditions of the goal.
Delegation provides the missing frame. By tying authority to purpose, context, and duration, delegation makes it possible to give agents freedom to act without giving them unrestricted control. But delegation only works when it is enforced through policy, evaluated at runtime, and integrated directly into how agents plan and execute actions.
The diagram in this post illustrates that shift. Authorization is no longer a gate at the edge of execution. It becomes a feedback signal inside the agent loop, shaping what actions the agent can consider next and how it responds when constraints are encountered.
In the next post, I’ll look more closely at what delegation really means in agentic systems. We’ll distinguish it from roles, impersonation, and scopes, and explain why delegation cannot live in identities or tokens. From there, we’ll explore how policy becomes the mechanism that makes bounded autonomy possible.
Photo Credit: AI Agent Saluting from DALL-E (public domain)
Thoughtful piece, but I wonder if there’s a category mismatch. Your framework assumes agents have persistent goals that can be delegated and constrained through policy. But if LLMs are stateless pattern matchers where “goals” are just temporary statistical biases from context (as the injective proof suggests), what exactly is being constrained?
The attacks you’re defending against exploit accumulated context across sessions, not weak authorization boundaries. No component-level policy can see breaches that emerge from individually compliant interactions.
Curious how your framework accounts for this—are you assuming something like persistent intentions emerges during inference?
Hey, Phil. Great post, and I agree that authorizing agents is tricky and needs to be done continuously. I also strongly agree with your other post that agents are not a good choice for a policy engine due to their probabilistic nature.
I wanted to mention several things that seem adjacent to what you're talking about here, that might pique your interest or feedback.
1. A supposition in many discussions about agents is that they have sameness across time and are thus worthy of identity that asserts that sameness. But if an agent changes its model or its training data or its policies, what is really the "same" about it from Time1 to Time2, such that it is worthy of having an identity that connects its existence at those two points? The only sameness in such a model might be the controller's access point, or possibly the agent's stored data used for RAG, or possibly the OAuth tokens it uses to authenticate to external systems. I'm worried that this issue is handwaved past by the designers of A2A and MCP, and represents a fundamental trust gap that can never be filled unless/until we figure out how to associate sameness with an agent in a reliable way. (This may be partly what PEG is alluding to with "stateless pattern matchers... just temporary statistical biases from context", or maybe that's a whole nuther point...)
2. I think the entire digital landscape, but ESPECIALLY agent land, is desperately in need of a concept that I call an "intent boundary", which I have written about here: https://dhh1128.github.io/papers/intent-boundaries.html
3. I 100% agree that the constraints you want to place on agents are mandatory, and I think there should be many more. I did some work on constrained delegation a couple years ago, and it is now becoming relevant to stuff I'm working on in verifiable voice (telco). It could also be applied to agents. See https://github.com/provenant-dev/public-schema/blob/main/gcd/index.md (this doc is KERI-oriented, but same principles could be applied more widely). Implicit in this is that KERI delegation is 2-way (has builtin mechanisms for the delegator holding the delegate accountable and transparent), whereas normal delegation is 1-way (transfer authority and then have no ability to monitor, revoke, prevent its redelegation, etc.).